机器学习笔记
机器学习与模式识别
Week1 聚类
典型算法
- k-means
- 线性的,球状的
- Chameleon变色龙
- 基于k紧邻图的层次聚类
- dbscan
- 基于密度(近邻)的传销聚类
Week2 聚类进阶
任意形状聚类的现有问题
- 谱聚类算法
- 时间复杂度通常不低于$O(N^2)$
- 基于图的算法 & 基于密度的算法
- 时间复杂度通常不低于$O(N^2)$
- 需要用户定义关键参数,影响聚类结果
- 基于代表点的算法
- 所选代表点的数量和分布可能不合适,导致其所反应的聚类信息产生扭曲
基于代表点的算法
基本思路
原始数据集 -> 选取代表点 -> 代表点位置调整(缩骨法) -> 聚合聚类 -> 最终聚类结果
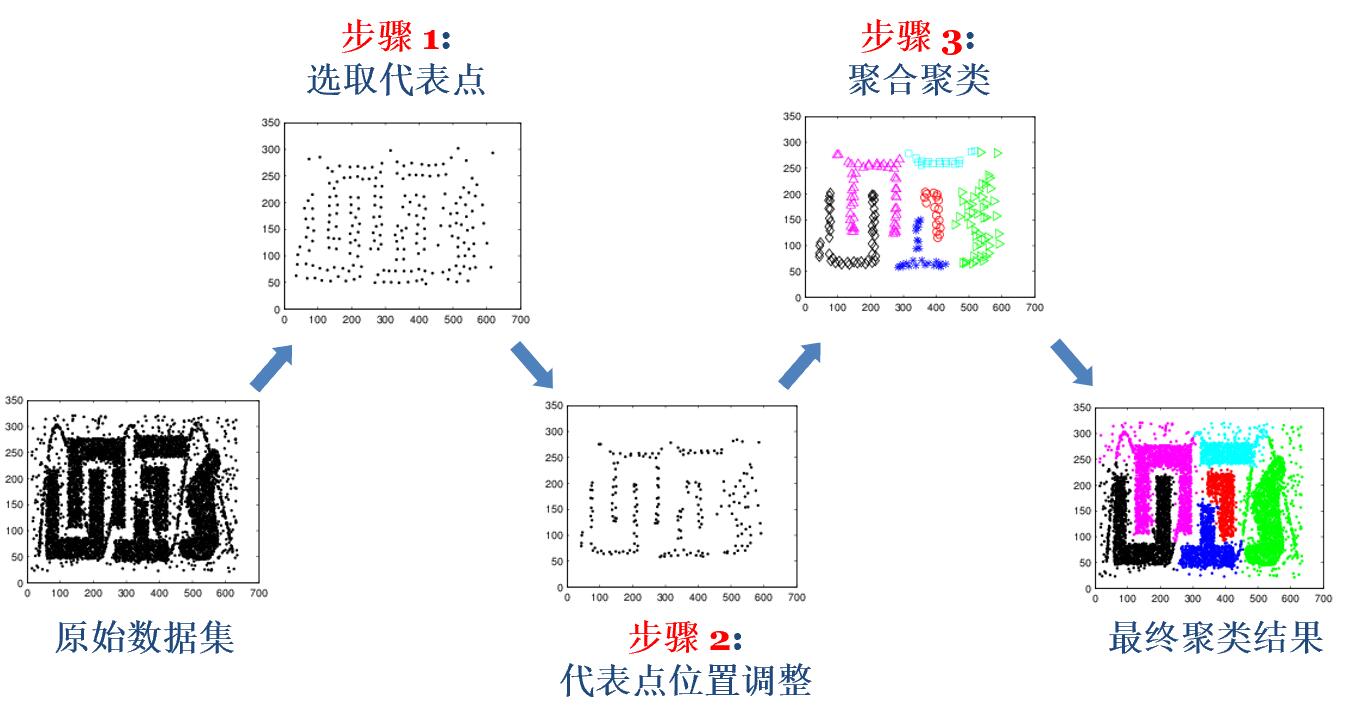
要求
- 快速选取代表点
- 利用K-means算法将原始大数据集划分成均匀连续分布的小数据团,将每个中心点作为代表点
- 代表点保留原始数据集的形状信息
- 使用直方图密度估计让K-means的起始聚类中心点均匀连续的分布
判断相似度:
- 位置近
- 密度近
- 接触面大
Week3 分类
分类的流程
- 将样本转化为等维的数据特征(特征提取)
- 样本必须具有相同数量的特征
- 兼顾特征的独立性和全面性
- 选择与类别相关的特征(特征选择)
- 建立分类模型或分类器(分类)
分类模型的评估
- 真阳性 TP(True Positive)
- 真阴性 TN(True Negative)
- 假阳性 FP(False Positive)
- 假阴性 FN(False Negative)
真假->预测是否正确
PN->预测结果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 PeiFang's Notes!